前言
通过上篇文章 我们了解 alloc 底层最终调用的是 _class_createInstanceFromZone 方法开辟内存空间 下面就来分析一下该方法做了什么?
_class_createInstanceFromZone (已去掉多余代码)
static ALWAYS_INLINE id
_class_createInstanceFromZone()
{
size_t size;
size = cls->instanceSize(extraBytes);//计算内存大小
if (outAllocatedSize) *outAllocatedSize = size;
id obj;
if (zone) {
obj = (id)malloc_zone_calloc((malloc_zone_t *)zone, 1, size);
} else {
obj = (id)calloc(1, size);//开辟内存空间
}
if (!zone && fast) {
obj->initInstanceIsa(cls, hasCxxDtor);//初始化 isa 指针和类关联
} else {
obj->initIsa(cls);
}
//isa 指针
if (fastpath(!hasCxxCtor)) {
return obj;
}
}
对于第一个 instanceSize() 方法
inline size_t instanceSize(size_t extraBytes) const {
if (fastpath(cache.hasFastInstanceSize(extraBytes))) {
return cache.fastInstanceSize(extraBytes);//从缓存中获取
}
size_t size = alignedInstanceSize() + extraBytes;
// CF requires all objects be at least 16 bytes.
if (size < 16) size = 16;
return size;
}
可以看到 在有缓存的时候 fastInstanceSize() 内部是16字节对齐的算法
size_t fastInstanceSize(size_t extra) const{
return align16(size + extra - FAST_CACHE_ALLOC_DELTA16);
}
而在首次初始化对象时调用 alignedInstanceSize() 方法 最终来到 word_align 方法 可以看出这是个8字节对齐算法
#define WORD_MASK 7UL // 64 位操作系统下代表7
static inline uint32_t word_align(uint32_t x) {
return (x + WORD_MASK) & ~WORD_MASK;
}
测试一下
x = 6 计算 (6 + 7) & ~7 (1011) & ~ 0111 ~0111 = 1000 相当于 (1011) & 1000 结果: 1000 结果为8字节 &~ 相当于: 右移 3 位 再左移 3 位
思考:有缓存的时候是 16字节对齐,而没有缓存的时候却是8 字节对齐,那实例对象究竟是 8字节对齐 还是16字节对齐呢?
带着这个问题 继续查看 _class_createInstanceFromZone 方法
if (zone) {
obj = (id)malloc_zone_calloc((malloc_zone_t *)zone, 1, size);
} else {
obj = (id)calloc(1, size);//开辟内存空间
}
void *calloc(size_t __count, size_t __size)
- count -- 要分配的元素个数
- size -- 分配的元素大小
先看一个 calloc demo
#import <malloc/malloc.h>
int main(int argc, const char * argv[]) {
@autoreleasepool {
void *p1 = calloc(1, 10);// 分配一个长度为 10 的连续空间
void *p2 = calloc(2, 20);// 分配两个长度为 20 的连续空间
NSLog(@"%lu",malloc_size(p1));
NSLog(@"%lu",malloc_size(p2));
}
return 0;
}
控制台输出结果:
2022-05-06 14:28:56.846074+0800 OCDemo[30323:94337] 16 2022-05-06 14:28:56.846980+0800 OCDemo[30323:94337] 48
通过上面的结果得出系统实际分配内存的时候是以16字节对齐的,对象的内部则是以 8 字节对齐
为什么要内存对齐?
内存是以字节为基本单位,cpu 在存取数据时,以 块 为单位,而不是以字节为单位存取,字节对齐后会减少 cpu 存取次数,以空间换时间 可以降低 cpu 开销,提高 cpu 访问速率
通过代码 打印 对象实际所占内存大小
@interface Student : NSObject
@property(nonatomic,copy)NSString *name;//8字节
@property(nonatomic,assign)int age;//4字节
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
Student *stu = [Student new];
stu.name = @"Terry";
stu.age = 18;
NSLog(@"%lu",malloc_size((__bridge const void *)stu));
}
return 0
}
2022-05-06 16:19:12.923648+0800 OCDemo[64446:197025] 32
上面的输出结果:32字节,8 + 4 + isa(8字节) = 20,16 字节对齐后为 32
对象本质
在 iOS 开发中 我们定义的对象、属性、方法在编译的时候做了什么,我们不得而知,通过 Clang 生成 cpp 文件(Swift 则是通过 SIL),可以帮助我们更好的去分析。
把目标文件编译成 c++ 文件
clang -rewrite-objc main.m
打开 main.cpp 文件 搜索 Student 类
#ifndef _REWRITER_typedef_Student
#define _REWRITER_typedef_Student
typedef struct objc_object Student;
typedef struct {} _objc_exc_Student;
#endif
extern "C" unsigned long OBJC_IVAR_$_Student$_name;
extern "C" unsigned long OBJC_IVAR_$_Student$_age;
struct Student_IMPL {
struct NSObject_IMPL NSObject_IVARS;
int _age;
NSString *_name;
};
搜索 NSObject_IMPL
struct NSObject_IMPL {
Class isa;
};
objc_object 的结构体里面存储了:isa 指针 + 成员变量的值,
即 对象的本质是 isa 加 成员变量的值
然后跟着 _class_createInstanceFromZone 方法继续往下走
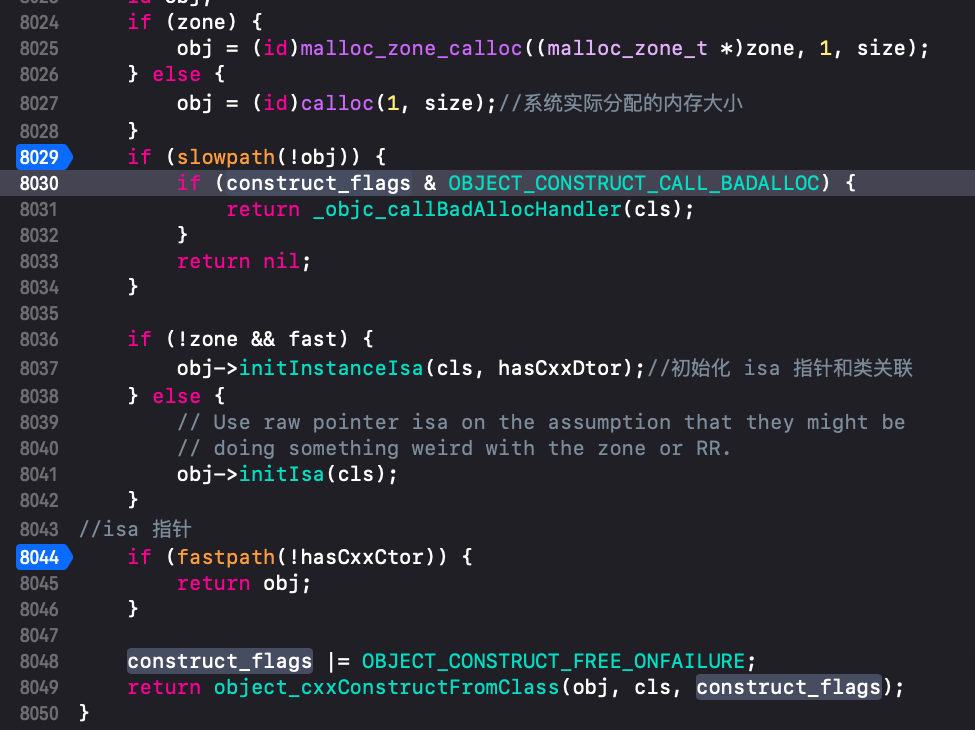
断点到这里后 通过控制台 po obj
断点到 8029 行代码 (lldb) po obj 0x0000000100a279a0 断点到 8044 行代码 (lldb) po obj <Student: 0x100a279a0>
在 8029 行代码 obj 没有与 Student 关联
当 obj 调用 initIsa()方法后
运行到 8044 行代码 obj 与 Student 进行了关联
总结
iOS 为对象开辟内存的流程:
- 通过 instanceSize() 先计算对象需要开辟的内存空间,对象内部是 8 字节对齐算法
- 系统通过 calloc() 分配实际所需内存空间 16字节对齐算法
- 最后调用 initIsa() 初始化 isa 指针 和 类进行关联
- cpu 是昂贵的资源,通过字节对齐算法 以空间换时间,降低开销,当我们看到源码字节对齐算法的时候,也要思考其背后的原因。